Adding an Amazon Bedrock Knowledge Base to the Forex Rate Assistant
Learn how to create a Bedrock knowledge base and integrate it with a forex rate assistant with RAG capabilities.
Introduction
In our journey of experimenting with Amazon Bedrock up to this point, we have built a basic forex assistant as the basis for further enhancements to evaluate various Bedrock features and generative AI (gen AI) techniques. Our next step is to integrate a knowledge base to the agent, so that it can provide information about foreign currency exchange in general.
In this blog post, we will define a representative use case for a RAG scenario for the forex rate agent, build a forex knowledge base, and attach it to the agent. Accuracy and performance of a gen AI application is also essential, so we'll conduct some tests and discuss challenges associated with RAG workflows.
About Knowledge Bases for Amazon Bedrock
Knowledge Bases for Amazon Bedrock is a service that provides managed capability for implementing Retrieval Augmented Generation (RAG) workflows. Knowledge bases can be integrated with Bedrock agents to seamlessly enable RAG functionality, or be used as a component in custom AI-enabled applications using API.
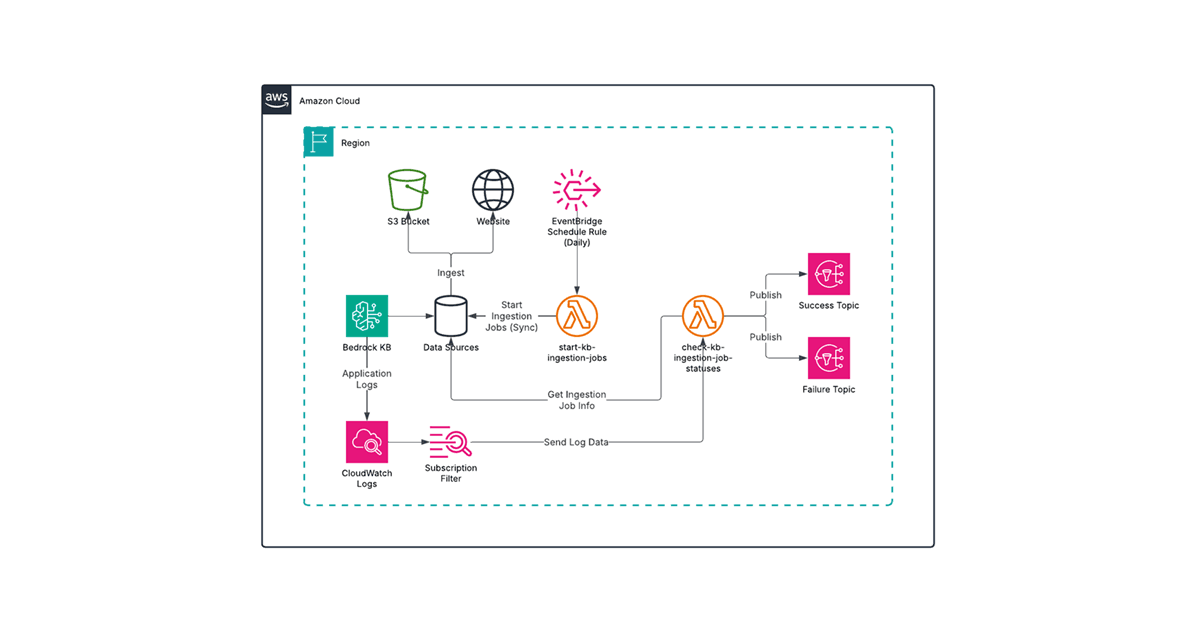
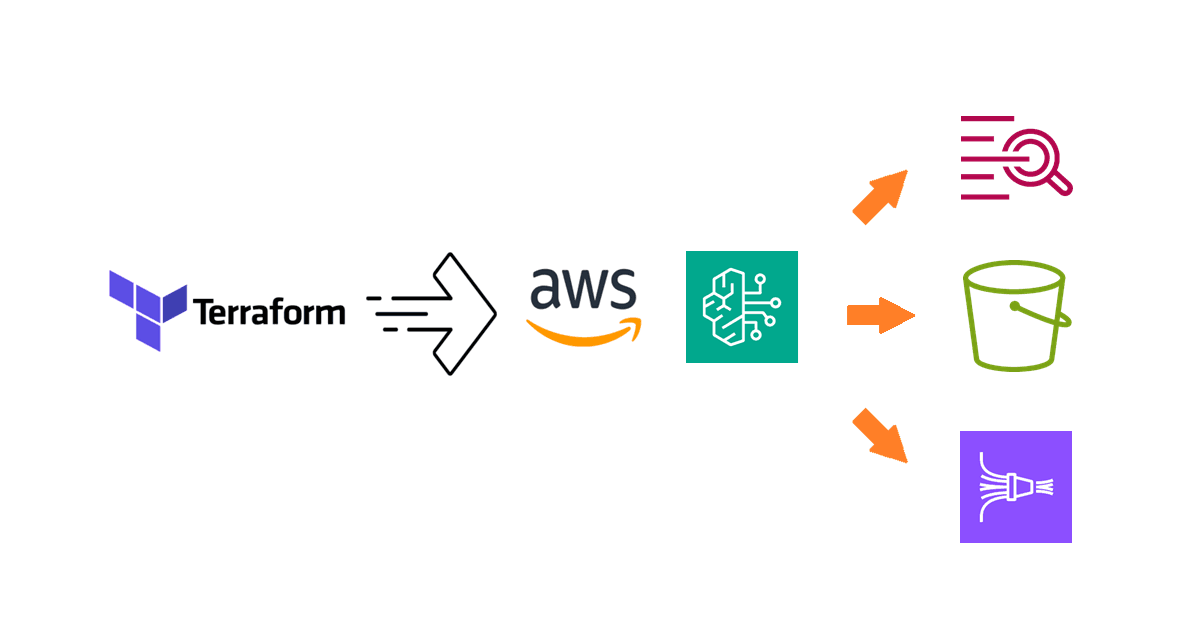
Knowledge Bases for Amazon Bedrock automates the ingestion of source documents, by generating embeddings with a foundation model, such as Amazon Titan or Cohere Embed, and storing them in a supported vector store as depicted in the following diagram:

To keep things simple, the service provides a quick start option that provisions on your behalf an Amazon OpenSearch Serverless vector database for its use.
Aside from native integration into a Bedrock agent, the Agents for Amazon Bedrock Runtime API offers both the ability to perform raw text and semantic search, and the ability to retrieve and generate a response with a foundation model, on knowledge bases. The latter allows the community to provide tighter integration in frameworks such as LangChain and LlamaIndex to simplify RAG scenarios. The runtime flow is shown in this diagram:

Enhancing the forex rate assistant use case
In the blog post Building a Basic Forex Rate Assistant Using Agents for Amazon Bedrock, we created a basic forex assistant that helps users look up the latest forex rates. It would be helpful if the assistant can also answer other questions on the broader topic.
While information about the history of forex would be useful, the Claude models already possess such knowledge so it would not make a great use case for knowledge bases. As I searched for more specific subtopics, I found the FX Global Code, a set of common guidelines developed by the Global Foreign Exchange Committee (GFXC) which establishes universal principles to uphold integrity and ensure the effective operation of the wholesale FX market. The FX Global Code is conveniently available in PDF format, which is perfect for ingestion by the knowledge base.
Requesting model access and creating the S3 bucket for document ingestion
Let's start with the prerequisites by requesting for model access. For the forex knowledge base, we will be using the Titan Embeddings G1 - Text model. You can review the model pricing information here.
Next, we need to create the S3 bucket from which the knowledge base will ingest source documents. We can quickly do so in the S3 Console with the following settings:
Bucket name: forex-kb-<region>-<account_id> (such as
forex-kb-use1-123456789012)Block all public access: Checked (by default)
Bucket versioning: Enable
Default encryption: SSE-S3 (by default)
Once the S3 bucket is created, download the FX Global Code PDF file and upload it to the bucket:

This is sufficient for our purpose. For more information on other supported document formats and adding metadata for the filtering feature, refer to the Amazon Bedrock user guide.
Creating a knowledge base along with a vector database
Next, we can create the knowledge base in the Amazon Bedrock console following the steps below:
Select Knowledge bases in the left menu.
On the Knowledge bases page, click Create knowledge base.
In Step 1 of the Create knowledge base wizard, enter the following information and click Next:
Knowledge base name: ForexKB
Knowledge base description: A knowledge base with information on foreign currency exchange.

In Step 2 of the wizard, enter the following information and click Next:
Data source name: ForexKBDataSource
S3 URI: Browse and select the S3 bucket that we created earlier

In Step 3 of the wizard, enter the following information and click Next:
Embeddings model: Titan Embeddings G1 - Text v1.2
Vector database: Quick create a new vector store

- In Step 4 of the wizard, click Create knowledge base.
The knowledge base and the vector database, which is an Amazon OpenSearch Server collection, will take a few minutes to create. When they are ready, you'll be directed to the knowledge base page, where you will be prompted to synchronize sync the data source. To do so, scroll down to the Data source section, select the radio button beside the data source name, and click Sync:

It will take less than a minute to complete, since we only have a single moderately-sized PDF document. Now the knowledge base is ready for some validation.
Testing the knowledge base
A knowledge base must provide accurate results, so we need to validate it against information we know exists out of the source documents. This can be done using the integrated test pane. To simulate an end-to-end test for the RAG scenario, configure the test environment in the Bedrock console as follows:
Enable the Generate response option (which should already be enabled by default).
Click Select model. In the new dialog, select the Claude 3 Haiku model and click Apply.
Click on the button with the three sliders, which opens the Configuration page. This should expand the test pane so you have more screen real estate to work with.
I've prepared a couple of questions after skimming through the FX Global Code PDF file. Let's start by asking a basic question:
What is the FX Global Code?
The knowledge base responded with an answer that's consistent with the text on page 3 of the document.

To see the underlying search results which the model used to generate the response, click Show source details. Similar to agent trace, we can view the source chunks that are related to our question, and the associated raw text and metadata (which is mainly the citation information). Some source chunks refer to the table of contents, which some refers to the same passage from page 3 of the document.

Next, let's ask something more specific, namely to give me information on a specific principle such as principle 15 which is on page 33 of the PDF file:

What is principle 15 in the FX Global Code?
Interestingly, the knowledge base doesn't seem to know the answer:

If I force the knowledge base to use hybrid search, which combines both sematic and text search for better response, some source chucks were fetched but it does not seem to include one with the text from page 33.

Since there are exactly five results, I figured that it might be limited by the maximum number. After increasing it to an arbitrary 20, the knowledge base finally returned a good response with the default search option:

This goes to show that just like agents, knowledge bases must be tested and fine-tuned extensively to improve accuracy. The embedding model as well as the underlying vector store may also play a part in the overall behavior of the knowledge base.
In any case, you've successfully created a knowledge base using Knowledge Bases for Amazon Bedrock, which can be integrated with your gen AI applications. To complete our experimentation, let's now integrate it with our forex rate assistant.
Integrating the knowledge base to the forex rate assistant
If you haven't already done so, please follow the blog post Building a Basic Forex Rate Assistant Using Agents for Amazon Bedrock to create the forex rate assistant manually, or use the Terraform configuration from the blog post How To Manage an Amazon Bedrock Agent Using Terraform to deploy it.
Once the agent is ready, we can associate the knowledge base to it using the steps below in the Bedrock Console:
Select Agents in the left menu.
On the Agents page, click ForexAssistant to open it.
On the agent page, click Edit in Agent Builder.
On the Agent builder page, scroll down to the Knowledge bases section and click Add.
On the Add knowledge base page, enter the following information and click Add:
Select knowledge base: ForexKB
Knowledge base instructions for Agent: Use this knowledge base to retrieve information on foreign currency exchange, such as the FX Global Code.

Click Save and exit.
Once the knowledge base is added, prepare the agent and ask the same first question as before to validate the integration:
What is the FX Global Code?
The agent responded with a decent answer. In the trace, we can see that the agent invoked the knowledge base as part of its toolset and retrieved the results for its use.

We also want to ask the agent to fetch some exchange rate to ensure that the functionality is still working:
What is the exchange rate from EUR to CAD?
The agent responded with the rate fetched from the ForexAPI action group, which is what we expected.

However, we run into issues when asking the second question from before:
What is principle 15 in the FX Global Code?
The agent responded with the inferior answer since we did not adjust the maximum number of retrieval results for the knowledge base.

Unfortunately, our issue now is that there is no way that I know of to provide the knowledge base configuration in the agent, so we are stuck. At this point, there's nothing we can do other than opening an AWS support case to inquire about the lack of support... That being said, another angle to look at the problem is that the quality of the source could also affect the knowledge base's search accuracy, which brings us to the topic of common RAG challenges.
Common RAG challenges
Let's examine the source chunk from the correct answer for the "principle 15" question from our knowledge base test:

This is also the text that was extracted from the PDF for embedding. Comparing it to the corresponding page in the PDF file, notice the following:
The chunk text includes information such as headers and "breadcrumbs" that are not related to the main content.
The text does not capture the context of the elements in the passage, such as the principle title in the red box and the principle summary in italic.

It's fair to think that undesirable artifacts and lack of structural context would impact search accuracy, performance, and ultimately cost. Consequently, it makes sense to perform some data pre-processing before passing the source documents to the RAG workflow. Third-party APIs and tools, such as LlamaParse and LayoutPDFReader, can help with pre-processing PDF data, however keep in mind that source documents may take any forms and there is no one-size-fits-all solution. You may have to resort to developing custom processes for pre-processing and search your unique data.
There are other challenges in building RAG-based LLM applications and proposed solutions which you should be aware of. However, some of them cannot be implemented in a managed solution such as Knowledge Bases for Amazon Bedrock, in which case you may need to build a custom solution yourself if you have a genuine need to address them. Such is the eternal quest to balance between effort and quality.
Don't forget to delete the OpenSearch Serverless collection
Be aware that Knowledge Bases for Amazon Bedrock does not delete the vector database for you. Since the OpenSearch Serverless collection consumes at least one OpenSearch Compute Unit (OCU) which is charged by the hour, you will incur a running cost for as long as the collection exists. Consequently, ensure that you manually delete the collection after you have deleted the knowledge base and other associated artifacts.
Summary
In this blog post, we created a knowledge base using Knowledge Bases for Amazon Bedrock which we integrate into the forex rate assistant to allow it to answer questions about the FX Global Code. Through some testing of the solution, we experienced some common challenges for RAG solutions and potential mitigation strategies. Although some of them are not applicable to Bedrock knowledge bases since it abstracts the implementation details, thus highlighting the potential need for a custom solution for more demanding scenarios.
My next step is to enhance the Terraform configuration for the forex rate assistant to provision and integrate the knowledge base, and to enhance the Streamlit test app to display citations from knowledge base searches. Be sure to follow the Avangards Blog as I continue my journey on building gen AI applications using Amazon Bedrock and other AWS services. Thanks for reading and stay curious!